Documentation Index
Fetch the complete documentation index at: https://whitepaper.neurobro.ai/llms.txt
Use this file to discover all available pages before exploring further.
Introduction
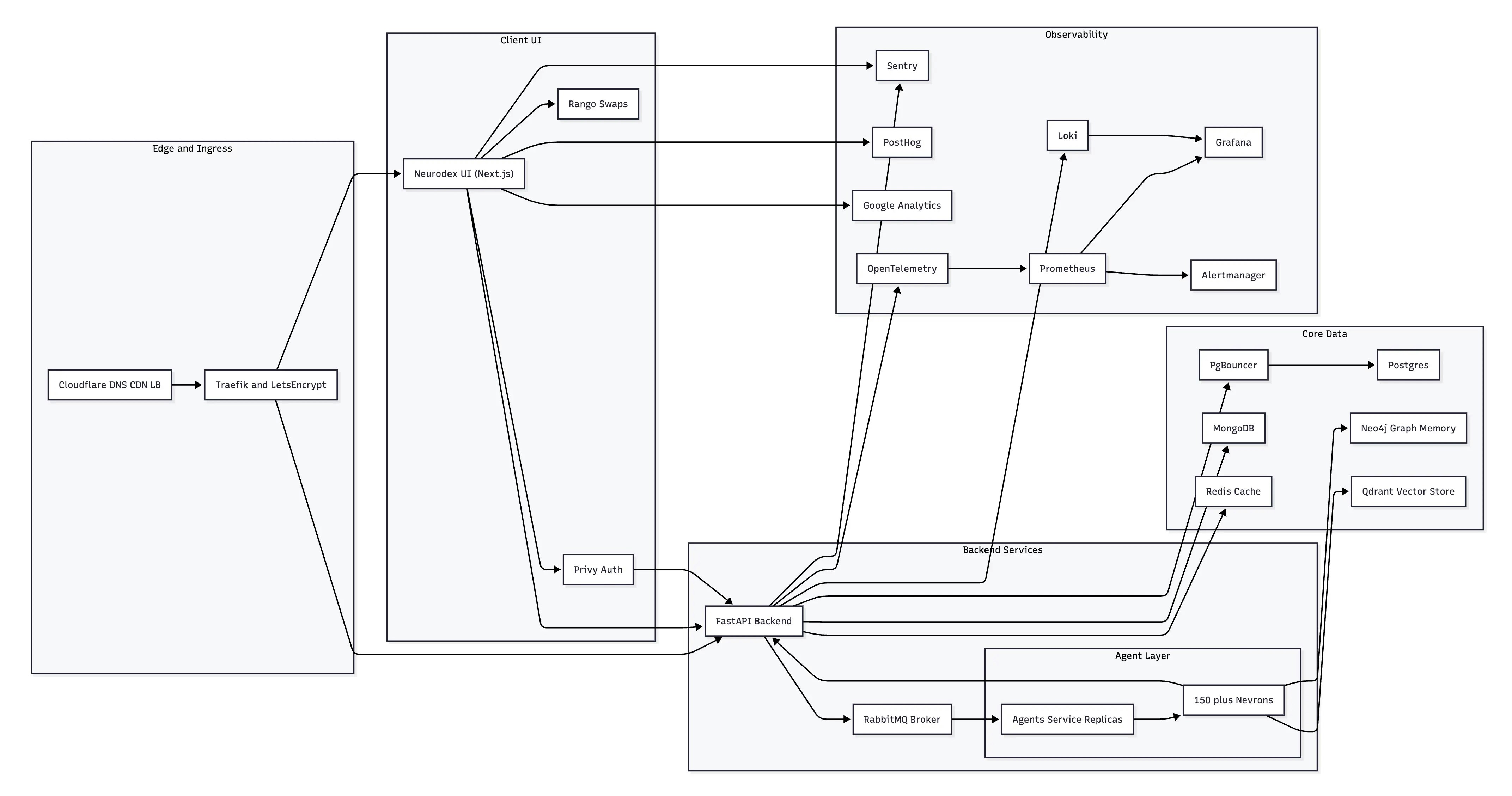
At Neurobro, we aim to build the new standard for AI information in crypto. This goal comes hand in hand with the excellence of the platform and implementation of real tech.Platform Microservices Architecture
The Neurodex Platform comprises four primary services:UI (Client)
Next.js frontend for user interactions
Backend (API)
FastAPI service for request handling
Neurobro Agents
Core intelligence service
Background Services
Background workers to keep the platform running smoothly
Underlying Services
Here’s the list of the underlying services, which make the platform work:Relational Database
PostgreSQL + PgBouncer
Document Database
MongoDB
Cache
Redis
Vector Store
Qdrant
Graph Database
Neo4j
SSL security
HTTPS via Let’s Encrypt and Traefik
CDN
Cloudflare
Error Tracking
Sentry
Analytics
PostHog + Google Analytics
Monitoring
Prometheus + Loki + Grafana + Opentelemetry + Alertmanager
Deployment
Docker + Kubernetes
Web Application Architecture
UI (Frontend)
UI (Frontend)
Framework
Next.js with SSR optimization
Authentication
Neurobro Pass (Google, Apple, Email OTP)
Swaps
Rango Exchange API integration
Backend (API)
Backend (API)
- Core Features
- Integrations
- FastAPI
- Database layer
- Message routing
- Major services integration
Neurobro Agents
Neurobro Agents
- Containerized replicas
- Workflow-based execution
- Real-time streaming
- Nevrons orchestration
- Nevrons Overview
There are 200+ Nevrons (swarm AI Agents) in total, each with a unique purpose and set of tools. Here are some examples:
Market Analysis
nevron23-26 - Market Sentiment Analysis
Technical Analysis
nevron31-33 - Technical Analysis
Research
nevron12-17 - Project Research (Focus on web, official data, publications, etc.)
On-Chain Scam Detection
nevron77 - On-Chain scam detection (Focus on suspicious onchain activity)
Background Services
Background Services
- Core Features
- Integrations
- Background workers to keep the platform running smoothly
- Data processing and analysis
- Market data updates
- User data updates
- Notification system
- Agent communication and Memory management
- etc.
Scalability & Performance
With scale comes complexity. There are many moving parts, and we make sure that the platform is scalable and performant. First of all, we scale the Nevrons swarm and the so-called “Agents Service” based on the load of background processes and real-time user requests.Load Distribution
Kubernetes workload balancing
Auto-scaling
Kubernetes auto-scaling
Low Latency
RPC streaming of processing results
Additional Resources
Nevron Documentation
Learn more about the Nevron framework and how it empowers a swarm of 200+ AI Agents
Changelog
See what’s new in the Neurodex
For technical support or architecture discussions, join our developer community.